Современное Big Data решение состоит из нескольких блоков, требующих совместной работы команд с разными компетенциями и интеграции набора Open-source и проприетарных программных компонентов:
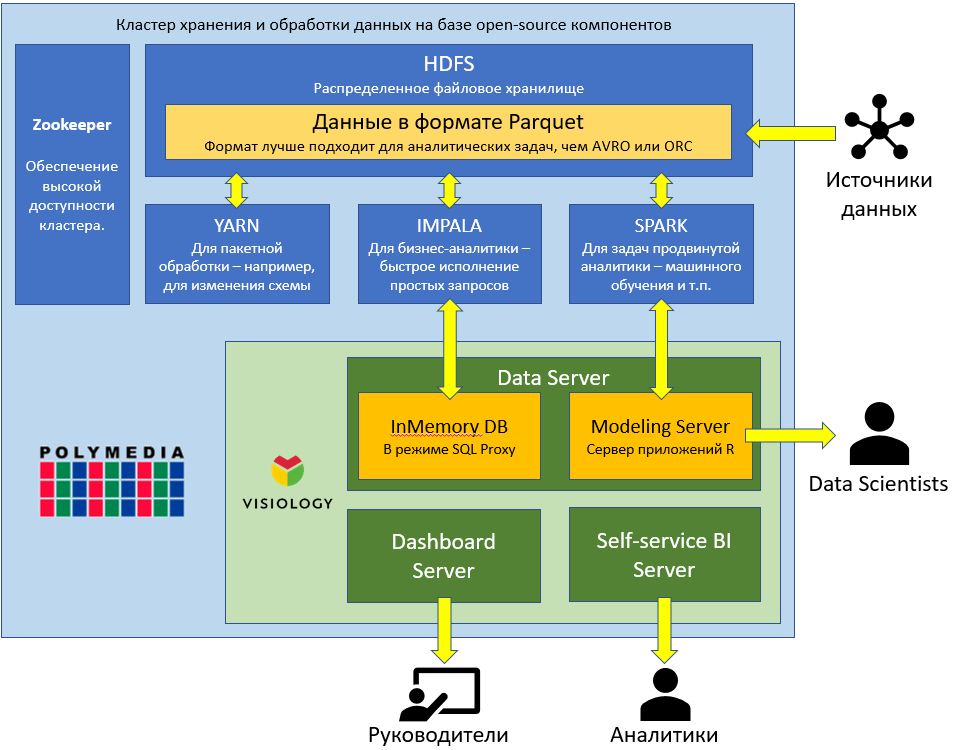
1. Техническое решение по сбору, хранению и обработке больших объемов данных, обозначенное на схеме как Big Data Tools. Такое решение, как правило, строится на основе стека Hadoop, так как он представляет хороший баланс между стоимостью, надёжностью и функциональностью.
2. Продвинутый анализ данных с использованием методов науки о данных (Data Science) и алгоритмов машинного обучения
3. Визуализация больших данных, а также создание интерактивных отчетов для руководства компании, сотрудников и клиентов (Business Intelligence). При этом используемая аналитическая платформа должна быть совместима со стеком Hadoop

Сборка решения Hadoop требует глубокой экспертизы. Специалисты Polymedia обладают необходимыми знаниями для построения оптимальной архитектуры аналитического Big Data решения и используют следующие технологии, обеспечивающие работу в реальном масштабе времени в условиях предприятия:
1. Многоуровневая сегментация данных. Например, самый часто востребованный, но относительно небольшой объем данных хранится в In-Memory базе данных ViQube платформы Visiology, а полный объем данных — в HDFS.
2. Кэширование на различных уровнях системы.
3. λ-архитектура для обеспечения обновления всех уровней данных в реальном времени.
Продвинутый анализ данных и моделирование с использованием
методов Data Science
Инструменты Data Science — это компьютерные методы и алгоритмы, позволяющие применить разделы математической статистики, теории вероятностей, численных методов оптимизации дискретного анализа для выделения знаний из данных.
| • Метрические методы классификации и регрессии
• Логические методы классификации • Критерии выбора моделей и методы отбора признаков • Градиентные методы обучения • Метод опорных векторов • Многомерная линейная регрессия • Нелинейная регрессия • Прогнозирование временных рядов • Байесовская теория классификации • Логистическая регрессия. Разделение смеси распределений | • Кластеризация
• Нейронные сети • Линейные композиции, бустинг • Эвристические, стохастические, нелинейные композиции • Ранжирование • Поиск ассоциативных правил • Задачи с частичным обучением • Коллаборативная фильтрация • Тематическое моделирование • Обучение с подкреплением |
С помощью методов Data Science можно оптимизировать производственные процессы без значительных капитальных затрат. Важной особенностью проектов Data Science является исследовательский характер, до проведения серьезного аудита данных невозможно дать точное заключение о достижимости тех или иных бизнес-целей. Для решения этой проблемы Visiology предлагает подход, позволяющий максимально снизить риски клиента, который сформирован в соответствии со следующими принципами.